Big Industries Academy


Introduction
If you grow as an employee, the company grows as well. That’s why we decided to setup the Big Industries Academy. The Academy is a platform for continuous learning by sharing expertise and knowledge within the team. In this context we are running on a regular base internal workshops to up-skill our team members with the latest technologies.
Our customers are increasingly asking for event-streaming solutions that enables the monitoring and managing of real-time data feeds. At Big Industries we strongly believe that Apache Kafka & NiFi are key technologies to address these requirements.
Demo Lab
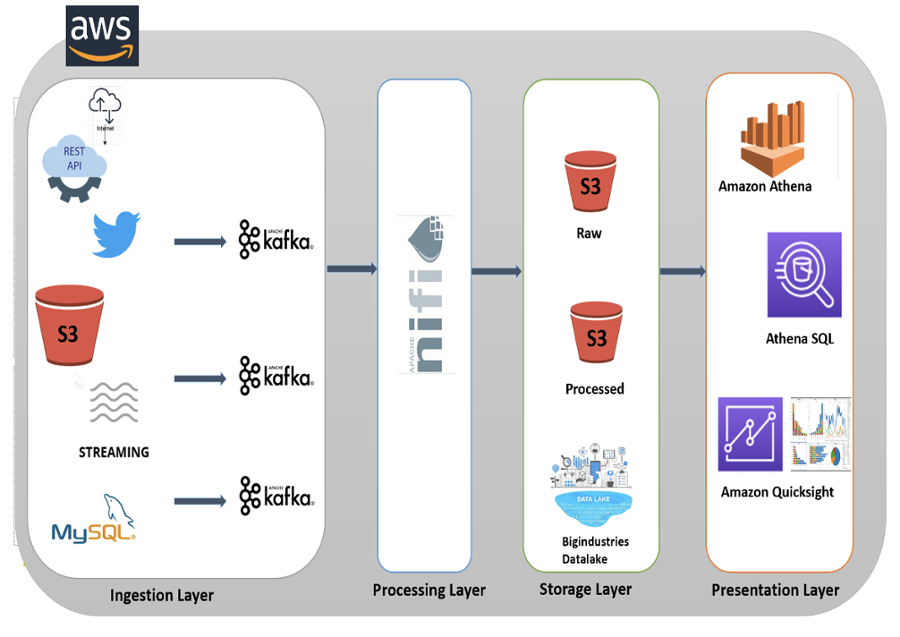
For the purpose of this workshop we have setup a demo lab and sourced the following aircraft flight and aviation data;
- AviationStack, an API giving access to real-time flight status and global aviation data.
- CSV files with data regarding new pilots joining an airline stored in an S3 bucket.
- self generated streaming data of customer ratings for each airline in an interval of 30 seconds.
- Twitter API, real-time feeds mentioning flights, airlines, airports, delays, take-offs, arrivals,...
- MySQL tables with data on flight incidents and root causes.
The goal of the exercises is to ingest the data from the different sources, followed by processing and storing the curated data. As last step the data is presented and visualised in order to perform analysis.
Lab Exercises

The Lab consists of the following exercises with complexity levels ranging from Entry level over Medium to Advanced;
- Transfer files from one Amazon S3 bucket to another S3 bucket without changing the format - Entry level.
- Autodetect and transfer files from one S3 bucket to another S3 bucket changing the format from CSV to JSON - Entry level.
- Generate random streaming data and write to a Kafka topic (Kafka producer implementation) - Entry level.
- Read the streaming data from the Kafka topic (output of exercise 3) and store the data in a S3 bucket (Kafka consumer implementation) - Entry level.
- Fetch data from the AviationStack API which will be sent to an S3 bucket via Kafka producer and consumer. Work with NiFi template variables to replicate the API extraction for other Endpoints - Medium level.
- Fetch data from a MySQL table and write to an S3 bucket (Full load). The job needs to be scheduled using Cron and run every day at 12pm - Medium level.
- Fetch data from a MySQL table and write to an S3 bucket (Incremental load). Only new records which are not ingested yet can be written to the S3 bucket using Kafka as processing engine - Advanced level.
- Fetch data from the Twitter API which will be sent to an S3 bucket via Kafka producer and consumer. Use the ConsumeTwitter processor in NiFi - Advanced level.
- Implement a Kafka Schema Registry using the NiFi inbuilt controller service - Advanced level.
- Create tables and views in Amazon Athena from the processed data stored in S3 - Medium level.
- Build dashboards from Athena with Amazon QuickSight to visualise the findings - Medium level.
Other technologies used to build the Demo Lab
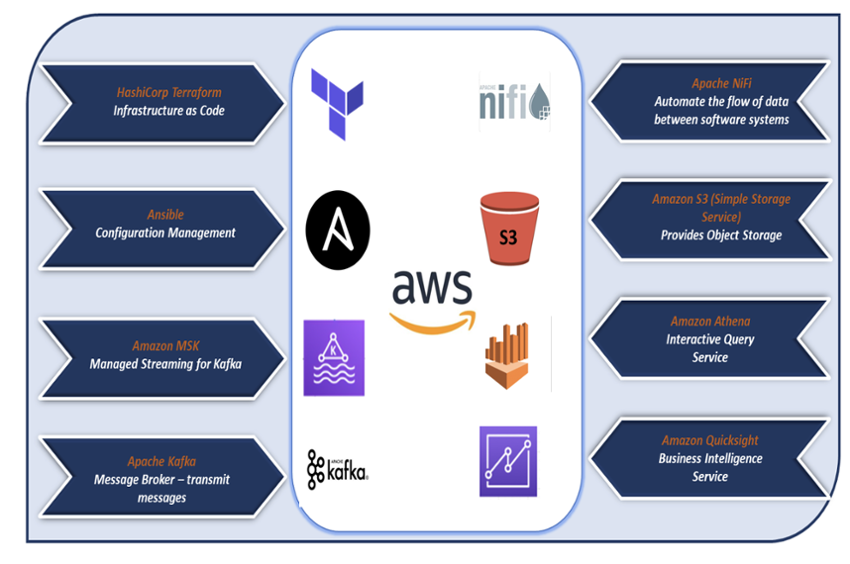 The main goal for the participants of the demo lab is to gain hands-on experience with Apache Kafka. However we built the demo lab from scratch and therefore used the following additional technology components;
The main goal for the participants of the demo lab is to gain hands-on experience with Apache Kafka. However we built the demo lab from scratch and therefore used the following additional technology components;
HashiCorp Terraform is an infrastructure as code tool that lets you define infrastructure resources in human-readable configuration files that you can version, reuse, and share. You can then use a consistent workflow to safely and efficiently provision and manage your infrastructure throughout its lifecycle.
The below AWS resources are provisioned automatically through Terraform.
- EC2 Instance - An Amazon EC2 instance is a virtual server in Amazon's Elastic Compute Cloud (EC2) for running applications on the Amazon Web Services (AWS) infrastructure.
- VPC - Amazon Virtual Private Cloud (Amazon VPC) provides a logically isolated area of the AWS cloud where you can launch AWS resources in a virtual network that you define.
- Security group - An AWS security group acts as a virtual firewall for your EC2 instances to control incoming and outgoing traffic. Both inbound and outbound rules control the flow of traffic to and traffic from your instance, respectively.
- S3 Buckets – Amazon Simple Storage Service (S3) provides object storage, which is built for storing and recovering any amount of information or data from anywhere over the internet. A bucket is a container for objects. An object is a file and any metadata that describes that file.
- Route table - A route table contains a set of rules, called routes, that determine where network traffic from your subnet or gateway is directed.
- Amazon MSK - Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that enables you to build and run applications that use Apache Kafka to process streaming data.
- NiFi installation
- Kafka client installation
- Creation of Kafka topics
AWS Athena is a serverless, interactive analytics service built on on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.
AWS QuickSight is a cloud-scale business intelligence (BI) service.
Team effort
A special thanks to Soundaram, Sander, Joanna, Kalil and Sandeep to design and implement this demo lab which will be further rolled out during other Academy events in the future.



