Big Industries Academy

Our team at Big Industries has been recently working on implementing TensorFlow open-source deep learning system on a Cloudera Hadoop Cluster. We found out that one of the challenges was trying to read the compressed MNIST data files from the Hadoop File System (HDFS). The example code that comes out of the box with TensorFlow assumes that the compressed files GZIP format reside on a local filesystem:
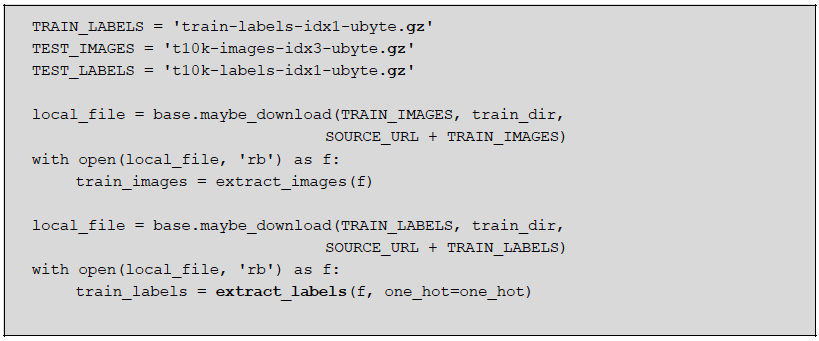
And the function 'extract_labels' is defined as following:
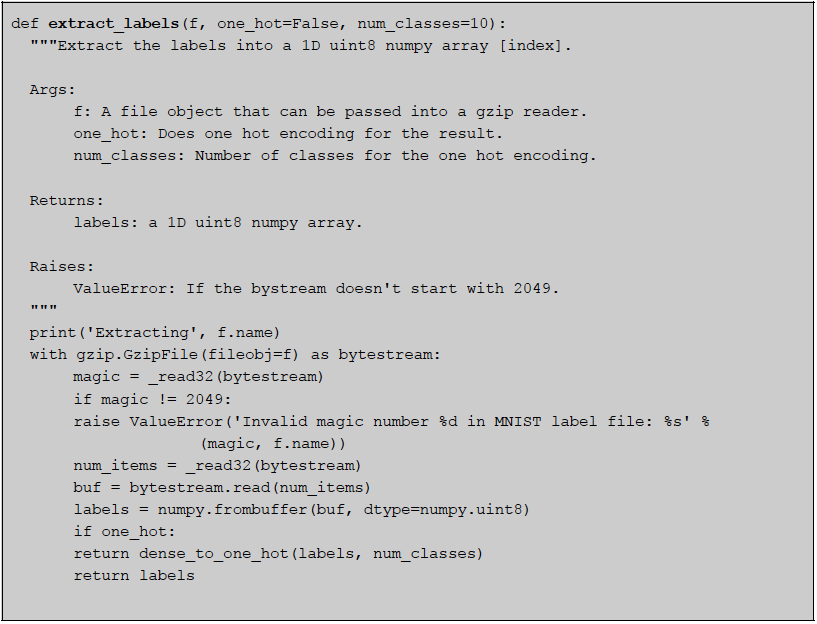
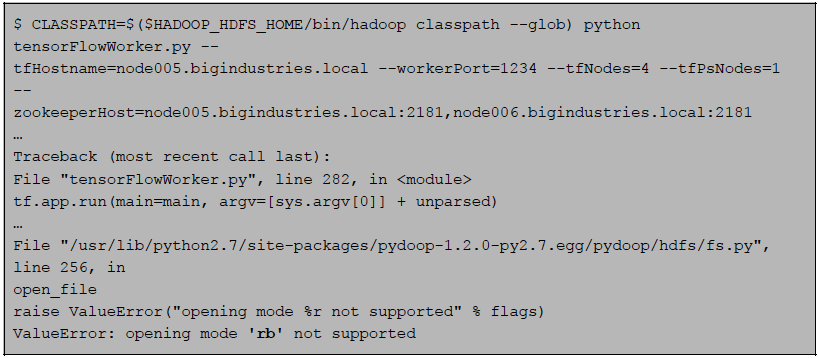
Since our MNIST files were on HDFS of a Cloudera Hadoop cluster, our first attempt was to use the Pydoop library. But this presented some obstacles because Pydoop can't read binary files, and also GZIP format is not splittable in Hadoop by default. If you try to read them as binary using Pydoop (keep in mind that 'pydoop.hdfs' is imported as 'hdfs'),

you get the following error:
Of course we could unzip the files for this example, and convert them to another format, but the TensorFlow code that we wanted to use expected them to be in GZIP format, and we wanted a solution that required the minimum amount of changes to the example code.
To overcome these, and satisfy our requirements, we turned to the standard library of our beloved Python, StringIO to the rescue.
According to the official documentation, StringIO module implements a file-like class, StringIO, that reads and writes a string buffer (also known as memory files). In other words, it is possible to use this module wherever a function expects a binary stream. so we came up with the following idea:
- Read the whole of GZIPped MNIST file from HDFS by using Pydoop,
- Pass the result to the 'extract_labels' function as a binary byte stream
- 'extract_labels' function will have received its input exactly in the format it expects
The implementation of the solution above was straightforward, (keep in mind that 'pydoop.hdfs' is imported as 'hdfs').

This technique helped us save the day, and overcome this challenge using the minimum amount of change in the code, therefore also helping maintenance of the code. Moreover, it is also possible to use the very closely related cStringIO module for performance enhancements. Of course, using the GZIP format is hardly the ideal format for performant data processing on HDFS, but more sophisticated solutions deserve another blog post, so stay tuned!




