Big Industries Academy

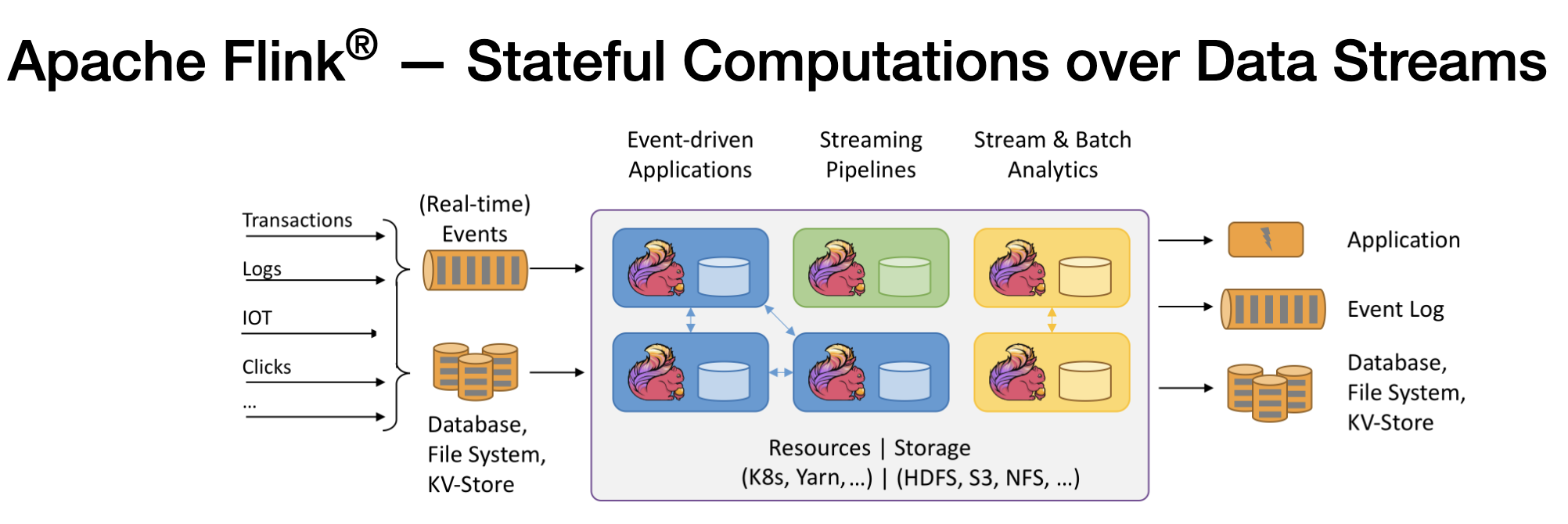
Apache Flink is an open-source distributed processing engine for large-scale data streaming, batch processing, and event-driven applications. It was designed to process large amounts of data with low latency and high throughput, making it ideal for real-time data processing and analysis.
Flink uses a dataflow programming model where data streams flow through a series of transformations that can be parallelised across a cluster of machines. Flink's core engine is built around a streaming-first architecture, which means that batch processing is implemented as a special case of streaming.
Flink provides a rich set of APIs and libraries for building scalable data processing pipelines, including SQL, batch and stream processing APIs, machine learning, graph processing, and more. It also has built-in support for fault-tolerance and state management, which allows it to handle failures and recover quickly.
Flink can be deployed on a variety of cluster managers like Apache Mesos, Apache YARN, Kubernetes, and standalone clusters. It also integrates with other Apache projects like Kafka, Hadoop, and Spark, making it a popular choice for many organizations for data processing and analytics.
Some Use Cases:
- Fraud Detection: Apache Flink can be used to detect fraud in real-time by processing a large volume of transactional data, identifying patterns, and alerting in real-time.
- Clickstream Analysis: Flink can analyze user clickstream data in real-time to understand user behavior, make personalized recommendations, and enhance user experience.
- Predictive Maintenance: Flink can analyze sensor data from industrial machines in real-time to predict equipment failures, reduce downtime, and improve productivity.
- Real-time Analytics: Flink can be used to perform real-time analytics on data streams such as log files, social media feeds, and financial data to generate insights, detect trends, and make data-driven decisions.
- Supply Chain Optimization: Flink can analyze supply chain data in real-time, optimize logistics operations, and improve supply chain efficiency.
- IoT Data Processing: Flink can process real-time data from IoT devices, such as sensors, cameras, and other connected devices, to enable intelligent decision-making and automation
- Machine Learning: Flink can be used to train machine learning models in real-time by processing large volumes of data streams and enabling continuous model training and improvement.
Overall, Apache Flink can be applied in a wide range of use cases where real-time processing and analytics of large volumes of data are required.

Sources:
Image: https://flink.apache.org/
Text: ChatGPT


