
Big Industries Academy
Exploring Messaging and Streaming Technologies Part1: Apache Kafka
This is the first article in a series of articles by Francine Anestis, where she looks at...

Big Industries Academy
HowTo? Series: Prepare for AWS Certified SysOps Administrator exam
With this How To? Series we want to Share Our Wisdom not only internally with our Big Industries...
Subscribe to our newsletter
Stay informed about our recent developments, newest projects and upcoming events


Big Industries Academy
Apache NiFi Explained
Apache NiFi, a robust, scalable, and configurable data processing and distribution system, has...

Big Industries Academy
Kudos to Muthiah
If you grow as an employee, the company grows as well. That’s why we decided to setup the Big...

Big Industries Academy
Workshop Operationalizing the Machine Learning Pipeline
Data Scientists andML Practitionersneed more than a Jupyter notebook to build, test, and deploy...

Big Industries Academy
Apache Iceberg: A Table Format for Large Scale Data
A comparison with Apache Kudu and Delta Lake
Apache Iceberg is an open source table format for...

Big Industries Academy
Kudos to Boris
If you grow as an employee, the company grows as well. That’s why we decided to setup the Big...
Big Industries Academy
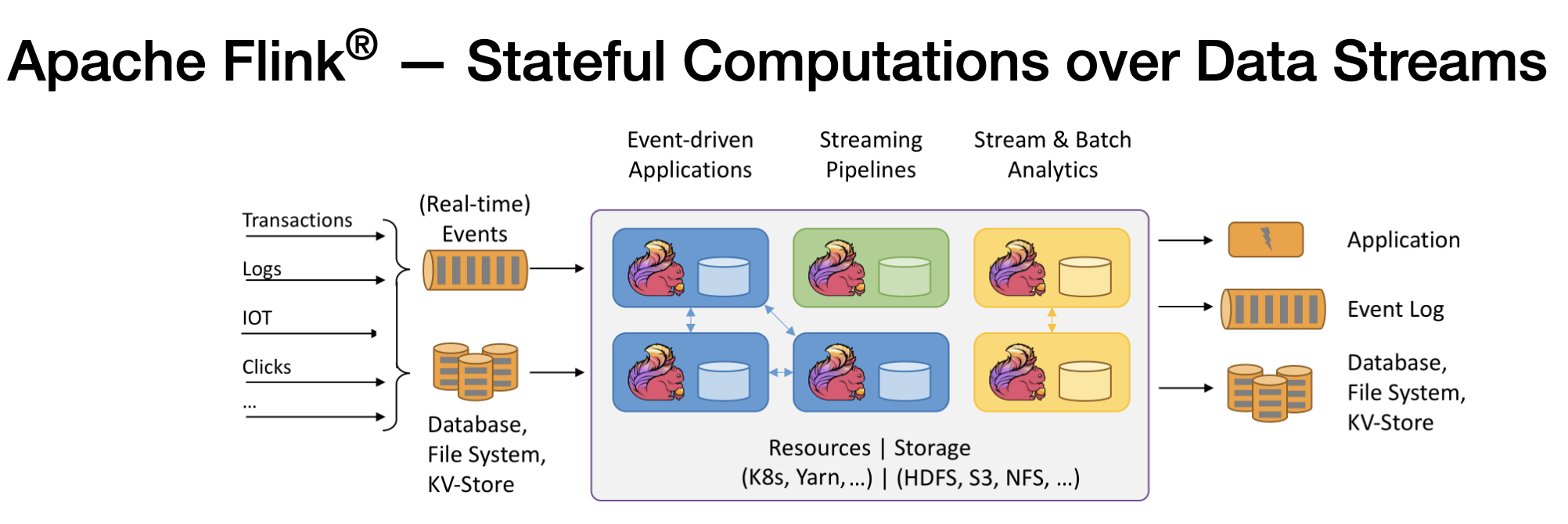
Apache Flink explained
Apache Flink is an open-source distributed processing engine for large-scale data streaming, batch...
Big Industries Academy
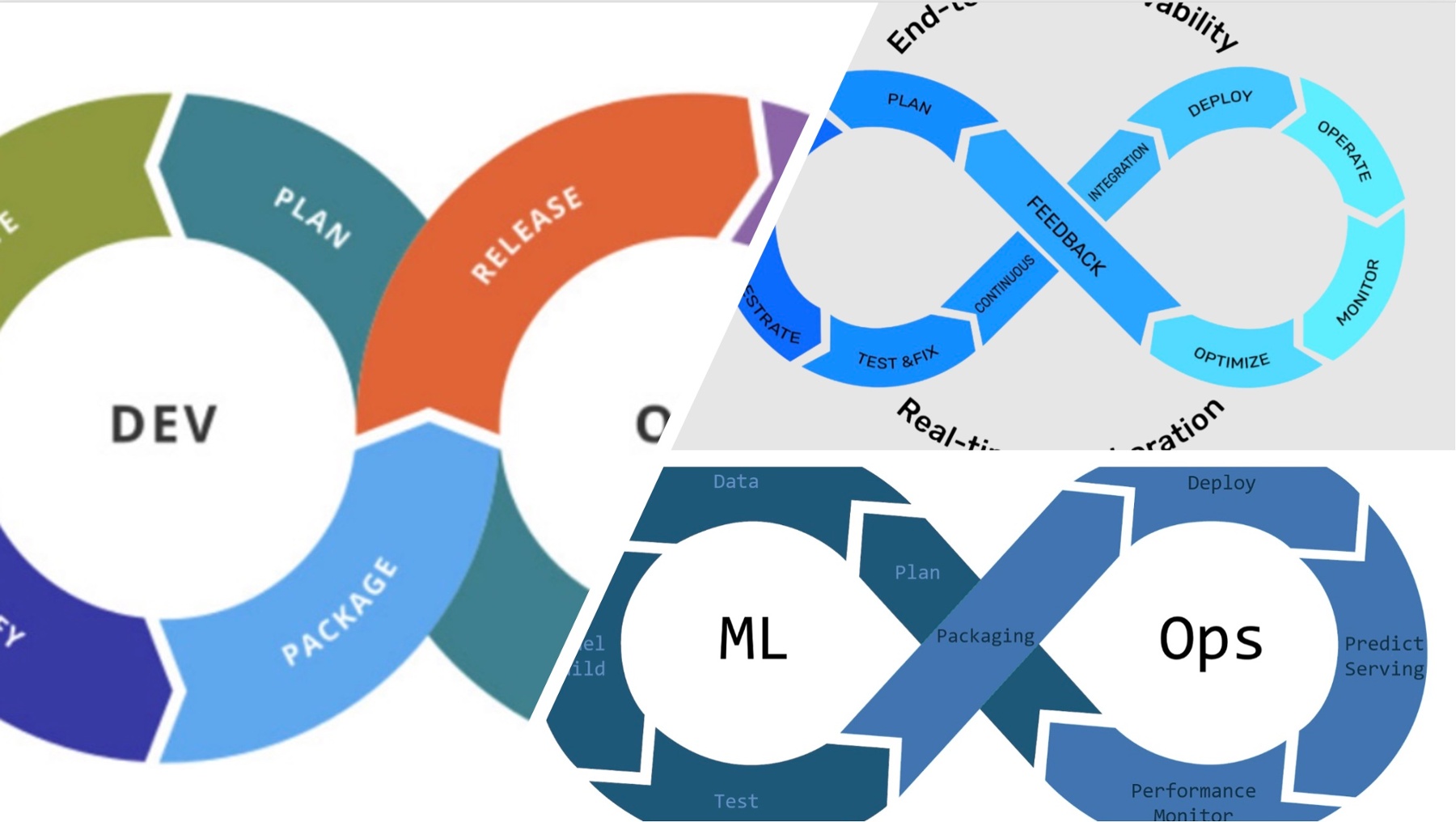
DevOps, DataOps and MLOps explained
What is the difference between DevOps and DataOps?

Big Industries Academy
HowTo? Series: JOLT - Part 1
Data comes in different shapes and sizes. Sometimes, we want to shape the structure of this data...